Openismus asked me to perform some benchmarks on Evolution Data Server. We wanted to track the progress of recent performance improvements and identify possible improvements. Therefore, I tested these versions of EDS:
- EDS 3.5.2 from June 4th 2012 - the latest development release.
- EDS 3.4.2 from May 14th 2012 - the latest stable release.
- EDS 3.2.3 from January 9th 2012 - shipped with Ubuntu 12.04 LTS.
- EDS 2.32.3 from April 21th 2011, - the last stable release of the GNOME 2 series.
- Maemo Fremantle's EDS fork from June 23th 2010, which was carefully optimized for the Nokia N900.
The code is in a phonebooks-benchmarks repository on Gitorious with a full auotools build, and with a script to build and test all these versions of EDS. So you can try this too, and you can help to correct or improve the benchmarks. See below for details.
EDS offers various APIs to access the address book. The traditional interface was EBook, which has served us well in GNOME 2 and Maemo 5. However, some APIs such as batch saving are missing in the upstream version. Also its asynchronous API doesn't follow the conventions established later by GIO. To overcome these EBook shortcomings, and to make efficient use of GDBus, the EBookClient API was added in EDS 3.2. We can even use the backend EDataBook API, and that lets us measure the overhead imposed by using D-Bus.
I tested the back-ends with different numbers of contacts. For each benchmark, and for each contact count, we create an entirely new private database. D-Bus communication was moved to a private D-Bus session. To avoid swapping, the maximum virtual memory size was limited to 2 GiB per ulimit command. This limit probably caused the crash of Maemo 5's EDS in the test with 12,800 contacts, but I have not checked that yet.
Contact Saving
These benchmarks simply store a list of parsed contacts in the address book. This simulates use cases such as the initial import of contacts upon migration or synchronization.
To avoid possible side effects from lazy parsing, we retrieve the attribute list for each contact before starting the benchmark. With EBook from Maemo 5 and EBookClient since EDS 3.4, contacts are saved in batches of 3,200 contacts. This partitioning was needed to deal with resource limitations in the file backend. All other EDS variants must save their contacts one by one.
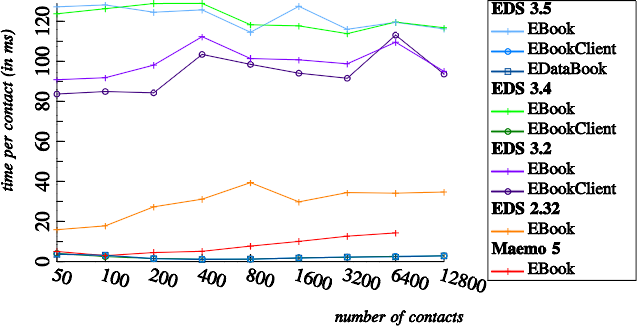
EBook, EBookClient, EDataBook implementation
As expected, the effort for contact saving grows quickly when not using a batch API. This is because a new database transaction must be created and committed for each contact. Things look much better when using the batch saving API which was available in Maemo 5 already, and was recently added to EBookClient:
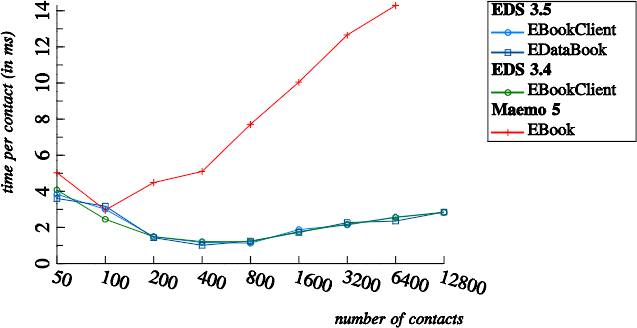
Batch saving performance of EDS 3.4+ is just excellent: Although slowly growing with the number of contacts, it remains below a threshold of 3 ms per contact even for 12,800 contacts. That growing effort can be accounted to growing attribute indices. The initial peak (until 50 contacts for Maemo 5, and until 400 contacts for EDS 3.4+) can be accounted to database setup cost.
In terms of performance there is no difference between using EBookClient or EDataBook (which avoids D-Bus).
Contact Fetching
A very basic, but essential, benchmark is fetching all contacts. To get a first impression I just fetched all contacts without any constraints.
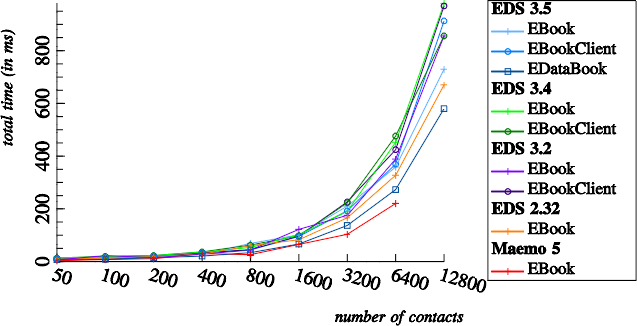
EBook, EBookClient, EDataBook implementation
Contact fetching performance decreased significantly during the EDS 3 series and then got better again: Fetching all contacts with 3.4 takes about 133% of the time that EDS 2.32 needs and even 225% of Maemo 5's time. With EDS 3.5 contact loading time is improving again, making the EBook version of EDS 3.5 comparable in performance to EDS 2.32. Git archeology and quick testing identifies Christophe Dumez's bugfix as the relevant change. Apparently the file backend didn't make optimal use of Berkeley DB transactions.
Still there is significant room for improvement, because:
- simple contact fetching with EBook 3.5 still takes 175% of the time Maemo 5 needs.
- EBookClient 3.5 is still 20% slower than EBook 3.5, and 64% slower than EDataBook.
This basic test shows already that the chosen client-server architecture of EDS causes a non-ignorable overhead.
It would be absolutely worth investigating how Maemo 5 reaches its far superior performance: After all it even beats EDataBook. I remember having spent significant time on avoiding vCard parsing and string copying. I also remember having replaced the rather inefficient GList with GPtrArray at several places. Some of the ideas have been ported upstream during Openismus' work for Intel. Apparently there are more gems to recover.
Fetching by UID
Fetching contacts by UID simulates lazy loading of contact lists: Initially, we only fetch contact IDs. We only fetch the full contacts when the device becomes idle, or when contacts become visible on screen. This approach is needed because even the fastest implementation (Maemo 5) needs several seconds to fetch any contact list of realistical size on mobile hardware. Another useful optimization we implemented on the Nokia N9 is fetching of partial contacts, that only contain relevant information, like for instance the person's name. EDS doesn't support this optimization.
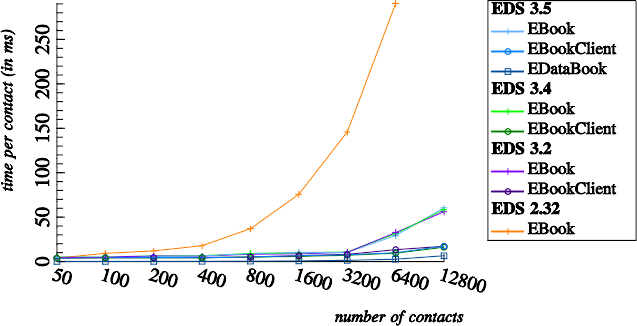
As a first test we fetch contacts one-by-one, without using any kind of batch API:

EBook, EBookClient, EDataBook implementation
The good news is that this chart shows quite constant performance for each client.
The bad news is that contact fetching is pretty slow: 3.9 ms per contact, as seen with EDS 3.5, translates roughly to 390 ms to fetch only 100 contacts on this hardware. Considering that typical mobile devices are roughly 10 times slower than my notebook, these numbers are disappointing. Especially if you consider that EDS 2.32 was about 4 times, and Maemo 5 even about 13 times faster. This are entirely different worlds. It should be investigated what causes this significant performance regression from EDS 2.32 to EDS 3.2+. One also should try to port the performance fixes of Maemo 5.
The performance reachable under ideal circumstances is shown by the EDataBook client. This only needs about 50 µs (0.05 ms) to fetch one contact by its id. Directly accessing the address book via EDataBook is about two orders of magnitude faster than the current EBookClient. That's the goal that EDS can, and should, aim for. Apparently a significant amount of time is spent on performing D-Bus communication, whereas the requested task can be performed by the backend within almost no time.
However, this data was acquired by fetching the contacts one by one. We can surely do better by using a batch API. That should drastically reduce the overhead caused, for instance, by D-Bus. But neither EBook or EBookClient provide an API to fetch contacts by lists of contact IDs. The thing that comes closest is filtering the contacts by a disjunction of UID field tests:
(or (is "id" "uid1") (is "id" "id2") ...)
So I tried that. The results for such queries, using batches of UIDs, look like this:

EBook, EBookClient, EDataBook implementation
This chart speaks for itself. To remain responsive and appear fluid while scrolling, applications should render at 60 frames per second. To reach that framerate newly visible contacts must be fetched and rendered within less than 16 ms. EDS apparently cannot meet that performance goal even on desktop computers. Considering the huge performance differences between client-server access and direct access, as seen when fetching contacts one by one, it seems very worthwhile to add dedicated support for fetching multiple contacts by UID. The most obvious approach would be adding a batch API in the spirit of e_book_client_add_contacts(). Another solution would be adding more fast paths to the query processing code.
Filtering
EBook, EBookClient, EDataBook implementation, the queries used
Contact filtering is relatively efficient when using fields such as last-name, for which indices are hit. Still, the D-Bus overhead is noticeable: EDataBook needs less than 60% of EBook's or EBookClient's time.

The times to match long prefixes and suffixes look quite similar when hitting indices.
The behavior of EBook for short name prefixes is a bit strange. The EBook API is now deprecated, but it could still be worthwhile to identify the issue causing this strange behavior, so that it can be avoided in the future:
Interestingly, there seem to be no functional database indices for email addresses or phone numbers in more recent versions of EDS:
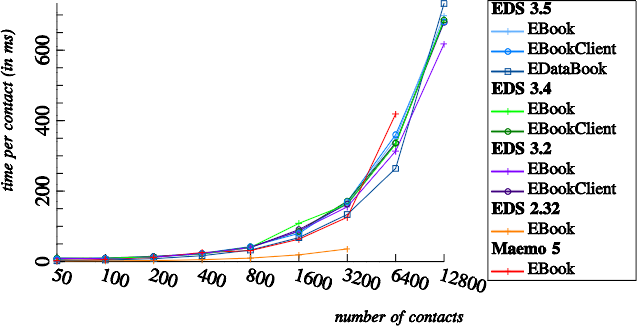
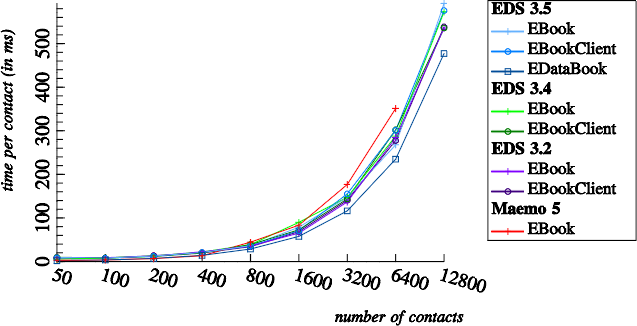
The behavior of Maemo 5's EDS is a bit surprising, as I know that Rob spent significant amounts of time on adding Berkeley DB based indices to that EDS version.
It might be worth optimizing index usage in EDS, because prefix and suffix searches are commonly used in mobile applications. Prefix searches need to be fast, for quick feedback during auto completion. Suffix searches need to be fast, for instance to provide instant caller identification.
Memory Usage
Memory is cheap those days. Still, especially on embedded devices, you should keep a close eye on the memory consumption of your software. Obviously, memory consumption grows with the number of contacts used:
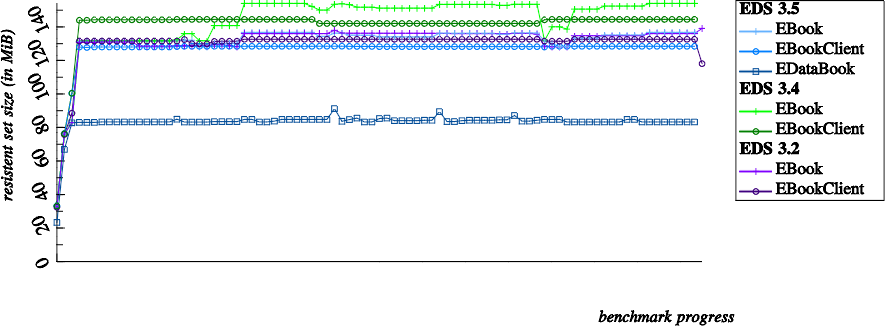
It's nice to see how memory consumption has reduced from release to release. It's also good to see that EBookClient seems to use slightly less memory than EBook.
You might miss the graphs for Maemo 5 and EDS 2.32. I had to drop them for this chart as they show serious memory leaks, preventing any useful examination. Apparently the leak really is in those versions of EDS: The EBook benchmarks for EDS 3.2+ are using exactly the same code but don't show this bad behavior.
Notice that I've accumulated the client's and the backend's memory consumption. This allows us to estimate the cost of EDS's client-server architecture. Apparently this architecture increases memory consumption by about 40% in these benchmarks.
While the RSS usage gives us information about the efficiency and correctness of the code, it's also interesting to check the virtual memory size needed by the benchmarks. Please take the following numbers with a reasonable grain of salt: I got these numbers by simply adding together the virtual memory size of the client and of the backend process, as reported by the processes' status file. A proper measurement would process the maps file to properly account for shared memory regions.
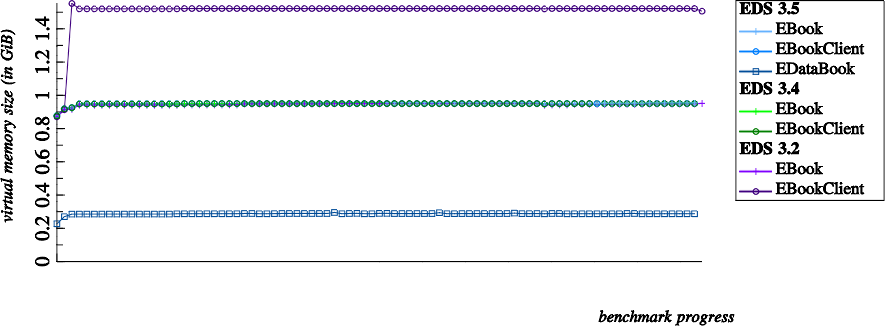
The first issue we notice is the massively increased memory usage of EBookClient 3.2. It's almost 40% more than the others. Fortunately, the issue seems to have been fixed already in EDS 3.4.
At first glance, the very low virtual memory usage of the EDataBook benchmark is impressive. It seems to consume only 40% of the client-server based benchmarks. Still, there is a fairly high chance that this huge delta must be attributed to my poor measurement here: Assuming perfect code segment sharing there only remains a delta of about 20 MiB, which would be nothing but the RSS delta of EDataBook and EBookClient. It would be nice to investigate this in more detail.
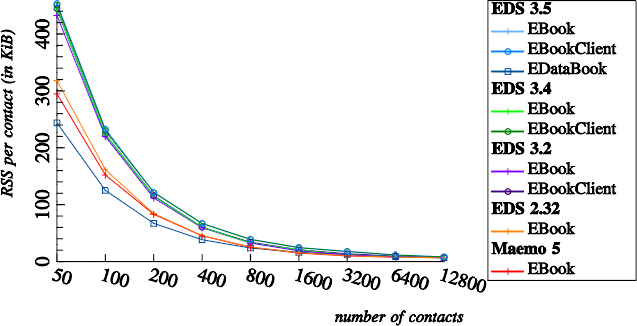
This chart shows the memory per contact after the contact saving benchmark. The overall memory usage per contact has grown dramatically by almost 40% in EDS 3+. The most efficient approach is apparently to directly access EDataBook, which consumes only 55% of the RSS per contact, compared to the client-server approaches.

This high memory usage per contact is a bit surprising since, after subtracting effects from library and database initialization, the memory usage per contact remained constant between EDS 2.32 and EDS 3.5. The parallel usage of both Berkeley DB and SQLite in the file backend might be to blame, but this is currently pure speculation from me.
The temporary regression in EDS 3.2 was apparently fixed. The increased memory usage of EBookClient and EDataBook over EBook is because the EBookClient and EDataBook benchmarks, in a slightly unrealistic bias for performance, store both the EContact and the VCard string for each contact.
Conclusions
The developers of Evolution Data Server have paid good attention to performance and have successfully implemented significant improvements. However, EDS releases regularly suffer performance regressions, and the performance of EDS still isn't good enough for usage in mobile devices. Fortunately the performance problems are solvable. Some fixes will be straightforward, such as adding more batch API (or fast paths) for query processing. Others will need careful performance monitoring: For instance when activating more database indices, to speed up queries, we must be careful not to slow down contact saving.
A not so trivial improvement would be adding a direct access API for reading the local database. The speed and memory usage measurements show the value of such API: Direct access is significantly faster than via D-Bus in most usage cases, and it seems to significantly reduce memory usage.
Another significant improvement should be finishing the file backend's transition to SQLite: Using two database backends in parallel significantly increases code complexity and has measurably bad impact on memory consumption.
Usage Instructions
The full source code of this project is in our phonebooks-benchmarks repository on Gitorious. You'll need a fairly recent C++ compiler because I also used this project to get more familiar with the new features of C++11. I've successfully tested g++ 4.6.3 and g++ 4.7.0. Clang 3.0 definitely won't work because of incomplete lambda support.
Other than that, you'll need Boost 1.48 to compile the benchmarks. The optional chart-drawing module uses ImageMagick++ and MathGL 2.0.2.
There is a simple script for building and installing the tested EDS versions. The configure script will give instructions.
To finally run the benchmarks just call src/phonebook-benchmarks, and to draw the charts run src/phonebook-benchmarks-mkcharts.
When doing your own tests that needs a non-trivial vCard generator take look at src/phonebook-benchmarks-mkvcards.
Outlook
It would be interesting to take a more detailed look at the virtual memory usage.
Also it would be educational to compare these results with other address book implementations. The first candidates I have in mind are QtContacts on Tracker and Tizen's native contacts API.
We didn't cover EBookView and EBookClientView yet. These views take a query and notify the application when the contact set matching the query has changed. Typically, every user interface needs to use them.
We also didn't talk about the calendar API yet.
Well, and most importantly we at Openismus would enjoy fixing the identified performance problems.
4 1
1 

















